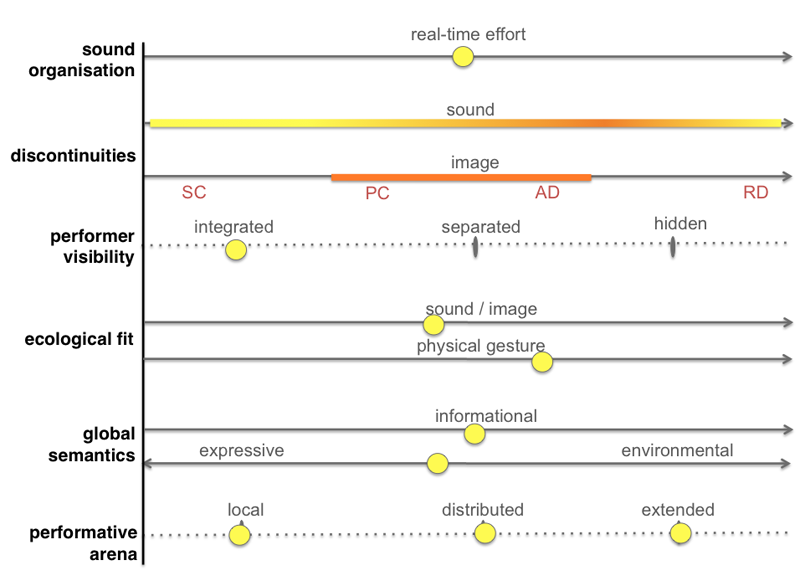
The Sound Organisation axis indicates that the interaction with my instrument entails medium Real-time Effort; it reflects the principle of sonic complexity: control and unpredictability are thresholded so that effort conveys expression. The model considers effort relative to cognitive processing and musical time, as well as the skills required to play the instrument/ system. The interaction with my instrument requires skills, namely to play the zither, and to integrate unexpected digital sounds in the musical logics. But the interaction is not very demanding in terms of cognitive processing, and it provides a sense of immediacy in the construction of musical time: my direct control over the zither sound makes the instrument extremely responsive, and digital constraints rule out undesired outcomes.
The two Discontinuities axes represent the sonic and visual dynamics. My music combines a few steady continuities (SC), with no intrinsic motion; a few progressive continuities (PC), where successive events display a similar interval of motion; many ambivalent discontinuities (AD), which shift the foreseeable logic of the music without disruption; and occasional radical discontinuities (RD), which are disruptive, prompting automatic attention. In the graphic of Figure 44, the orange gradient on Sonic Discontinuities shows that the music is more discontinuous than continuous: the strongest orange is closer to radical discontinuities than to progressive discontinuities. Nevertheless, the yellow gradient reaches the left extreme and the right extreme of the axis, showing that the music combines all types of continuities and discontinuities. Conversely, the visual motion solely includes ambivalent discontinuities and progressive continuities. Both are constant in visual dynamics, hence the stripe on Visual Discontinuities is orange, with no yellow gradient. The Visual Discontinuities axis shows that the work complies with the principle of visual continuity: the image exhibits no radical discontinuities, which would attract automatic attention and subordinate audition.
The Performer Visibility axis represents my location relatively to the visual projection. The yellow dot on Integrated reflects that the image is projected over me, functioning as a stage scene. There is no dot on Hidden because I am always visible, and no dot on Separated because I never exit the frame of the visual projection.
The two Ecological Fit axes represent the audio-visual relationship. The Sound/ Image axis represents the audio-visual mapping and its relation with sound diffusion; the Physical Gesture axis represents the relation between my physical gesture and the audio-visual output. The global fit of mapping, sound diffusion and gesture corresponds to the middle point of an imaginary segment uniting the two yellow dots, one on each axis. It does not require direct graphic representation because the middle point between two dots is straightforward; I opted for two axes so as to provide more cues about the work. The global Ecological Fit allows for extrapolations about perceptual binding and prioritisation. On the right side, high level of fit indicates conclusive interpretations of causation, which make us prioritise fitting information over non-fitting. On the left side, low fit indicates no convincing sense of causation, i.e. weak perceptual binding. Medium fit indicates a fungible audio-visual relationship.
In the graphic representation of my work, the dot on Sound/Image represents the fungible audio-visual mapping, as well as the fungible relation between 3D sound (i.e. digital sound spatialisation dependent on visual dynamics) and inverted stereo diffusion. The fungible mapping combines synchronised components, partially related components, and unrelated components. It creates a sense of causation, and simultaneously confounds the cause and effect relationships. The same happens with the audio-visual relationship in space. The combination of 3D sound and inverted stereo diffusion creates a sense of causation because the speed at which the sounds move through the speakers equals the virtual camera speed. At the same time, it confounds the cause-effect relationships because the direction of the sound source does not fully correspond to the visible sound emitter in the digital 3D world, i.e. the visible elevation in the foreground terrain (see chapter 5.6). We can hear the sound from two opposite directions, but only one corresponds to the sound emitter on the screen.
The dot on Physical Gesture is more to the right, because of the direct correlation between my gestures and the acoustic zither sound. It still indicates medium fit because that correlation is not clearly perceivable. There are several reasons for this. Firstly, the visible gesture is often not proportional to the loudness of the zither sound. Secondly, at times I “disappear” within the visual projection, particularly as I dress in white: my shadow over the projection outlines my physical body, yet my gestures are not clearly perceivable because the body is also a projection surface. And thirdly, the digital sounds are at times undistinguishable from the acoustic, namely when I activate audio sample bank 2, which includes recordings from the zither.
The two axes from Global Semantics indicate that the work entails Informational, Expressive and Environmental dimensions. The previous section of this chapter explained why the model can visualise Expressive and Environmental semantics on a single axis: they are inversely proportional. Expressive denotes a focus upon the performer, related with Emmerson’s notion of local functions [2007] and Ceciliani’s notion of centripetal performance tendencies [2014]; Environmental denotes a focus upon the environment, related with Emmerson’s field functions [2007] and Ceciliani’s centrifugal tendencies [2014]. Similarly to Emmerson, I do not play down this division.
The yellow dot on Expressive/ Environmental Semantics shows that the expressive dimension of my work is slightly stronger than the environmental. There might be as many factors conveying Expressive semantics as factors conveying Environmental semantics, but some are more influential than others – the product exceeds the sum. The Expressive dimension of the work derives from several factors. One, the audience’s sitting position, directed to me. Two, my central position relatively to the visual projection. Three, the pathos of my playing techniques. Four, the sound source placed next to me on stage (the zither amplifier). The Environmental dimension of the work derives from several factors as well. One, from the digital 3D world (an environment per se) and the overall continuity of visual dynamics. Two, from the size of the projection and my integrated position in front of the screen (in the threshold to the virtual world). Three, from the environmental aspects of the sonic construction. And four, from the sound system placed around the audience.
The Informational Semantics axis summarises the amount of informational load inherent to the work. It represents the extent to which the mechanics of an instrument/ system are revealed, as well as the figurative or symbolic qualities of sound and image. The yellow dot on the axis shows a medium level of informational load. Its middle position results from evaluating several aspects. The fungible audio-visual relationship entails informational load, because it explores perceptual cues so as to create a sense of causation; but not much, because the base cause-effect relationships are confounded. The figurative aspect of the sonic construction entails informational load as well; but not much, because one is led to strip perception from conclusive causes and meanings. The image is more loaded, as it represents an imaginary 3D world.
The Performative Arena axis shows a yellow dot on each discrete point, indicating that the work conveys three modes of spatial presence. The arena is Local because there is an amplifier on stage, and one is often led to focus on the performer’s expressiveness in physical space. The arena is Distributed because a double inverted stereo system is placed around the audience, and attention often drifts from the performer, so as to focus upon the environment, or internal states. Furthermore, the arena is Extended because there is a big projection of a digital 3D world that morphs with sound; because the audio-visual relationship explores perceptual cues, conveying one’s sense of spatial presence in the virtual space beyond the screen; and because the figurative sounds from sample bank 1 can transport the mind to imaginary natural environments.
The Performative Arena axis provides information that the other parameters do not specify. The dot on Local shows that at least sometimes the performer has protagonism over the environment: this specifies Performer Visibility, with its dot on Integrated (in Ikeda’s Superimposion the performers are not protagonists). The dot on Distributed specifies that a sound system is placed around the audience (environmental semantics could derive from other factors, such as the qualities of sound and/ or the image). And the dot on Extended indicates that the image has figurative qualities (bi-dimensional abstract graphics would not extend the arena). The arena could be extended through the sonic construction alone, yet the dot on medium Ecological Fit permits disambiguation, because it denotes that the audio-visual relationship applies perceptual cues.
Blurring the distinction between the notions of instrument, piece and performance conveys the description of my practical work and the discussion of the parametric model; indeed, the model represents instrument, piece and performance at once. When using the model to parameterise an audio-visual performance work we must consider every detail, so as to summarise the combination with axes and dots. The model’s level of abstraction encourages the analysis of how all aspects of the work combine, as much as it encourages the separate analysis of each aspect.